DAST Essentials URL configuration
The DAST Essentials crawlers have various intelligent algorithms that aim to reduce the number of pages crawled automatically. These algorithms are necessary and beneficial because, in web applications, there are often views on data for which scanning one example representative view covers the other views. For example, if you have a retail website with thousands of products, each with an individual product page, scanning each product would be time-consuming and redundant, as the code for adding something to the basket or leaving a product review is the same, regardless of the product. In this case, a security scan that scans one example page would be the ideal solution.
To access the URL configuration settings, select a target, then select CONFIGURE > URLs tab.
Allowed URLs
DAST Essentials only scans pages and requests that are subpaths of your target URL to avoid scanning additional targets that are out of scope for your target. However, modern applications often send requests to various back-end APIs, primarily JavaScript. If these APIs are not a subpath of the target URL, they will initially not be scanned, but you have the option to allow us to do so by adding URLs to the permitted URLs.
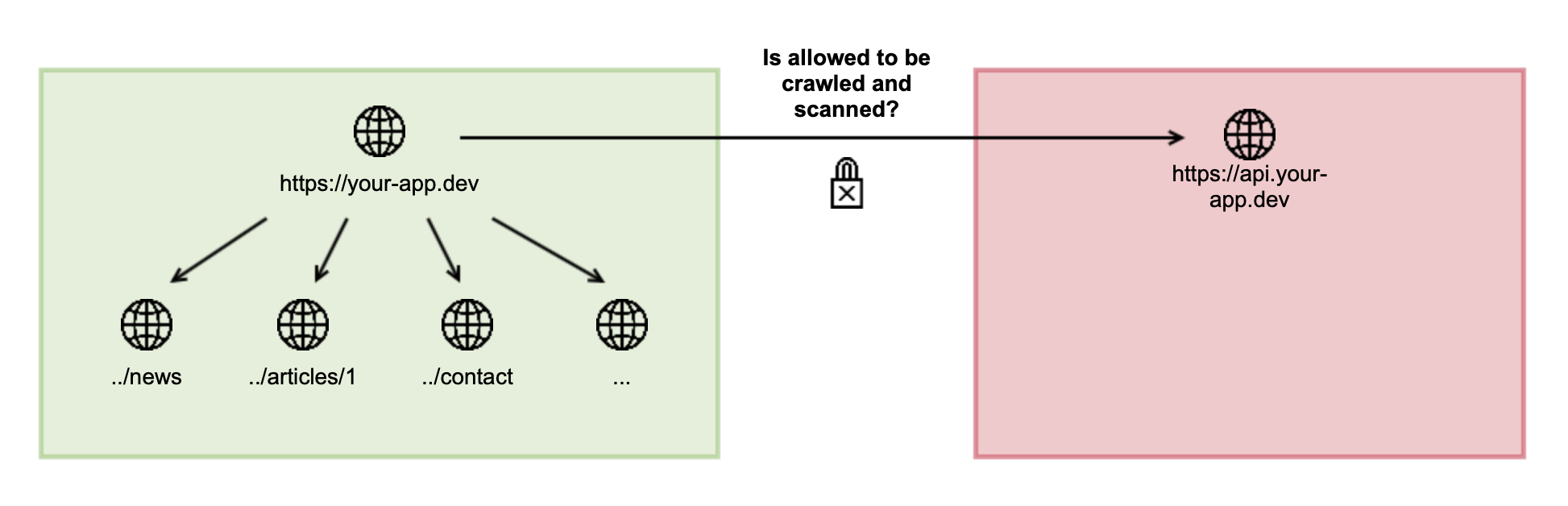
The allowed URLs will also be considered for navigational links in your web application during crawling, for redirects, and, as mentioned above, to check if a request should be scanned or not. You can specify allowed URLs in the configuration of your target on the URLs tab. By default, you will be allowed to add allowed URLs that are subdomains of your target URL. However, if you require a different URL to be allowed for scanning, contact Veracode Technical Support to verify that you are entitled to perform scans against the domain you want to add.
Afterward, the internal check of the crawler will succeed, and the allowed URL will be crawled and scanned as well.
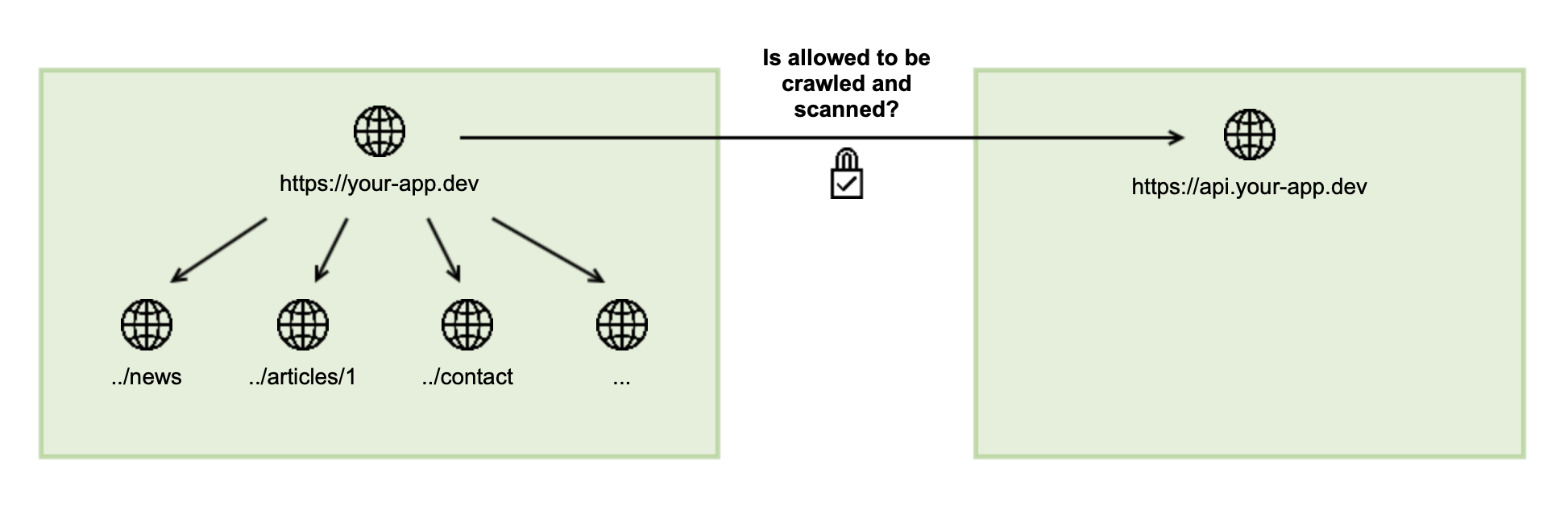
Denied URLs
To improve scanning speeds for web applications with large number of pages you can add page URLs to the Denied URLs list to exclude the pages from the scan.
By adding a URL to the denied URLs in a target, you can ensure that this URL and all subpaths are no longer crawled and scanned. This might, for example, make sense if your application has one or multiple modules which should be excluded:
This will ensure that the denied URL and its subpaths are no longer scanned.
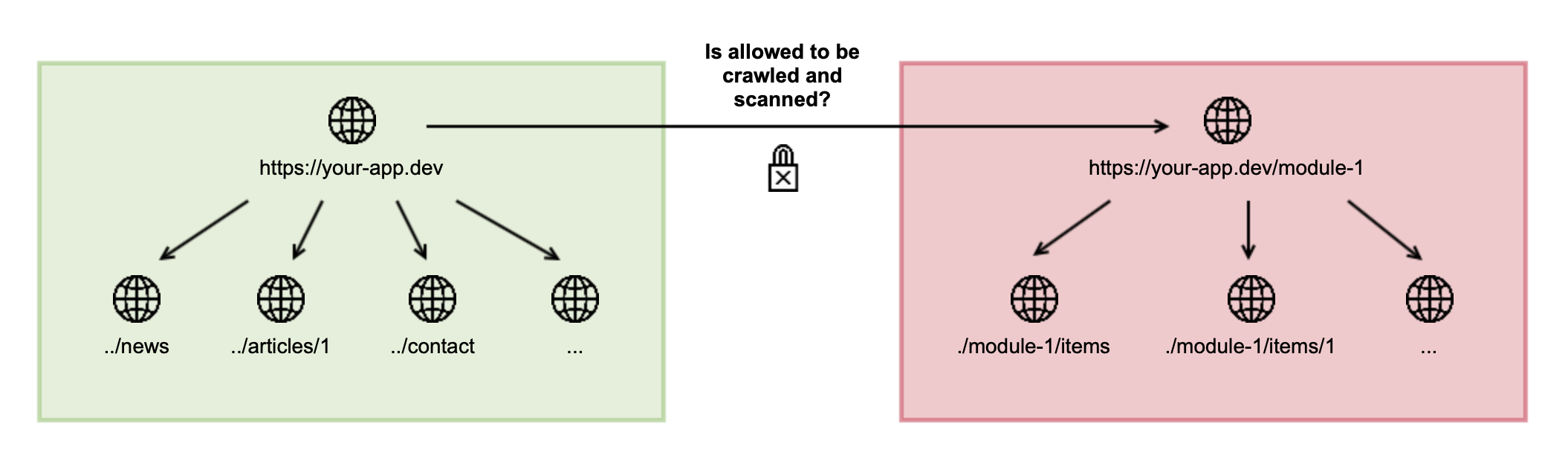
Grouped URLs
To improve scanning speeds for web applications with a large number of pages, you can add the page URLs to the Grouped URLs list to crawl and scan these pages only one time.
The grouped URLs allow you to specify a pattern to group-specific URLs and only crawl them once. This is especially useful if you have an online shop and the URL has a fixed structure containing a category and item name. Usually, these names are in text form for SEO purposes, which causes the crawler not to group them automatically.
To specify a grouped URL, use the star character (*) to define a part that should be grouped. A concrete example is described in the following to understand better how the grouping works.
Before specifying the grouped URL, the following URLs are all treated as being unique and are crawled individually:
www.your-app.dev/shop/shirts/shirt_s_bluewww.your-app.dev/shop/skirt/long_royal_bluewww.your-app.dev/shop/shirts/shirt_blue_trade
After specifying the grouped URL pattern www.your-app.dev/shop/*/ from the above list, only the first one will be crawled, and the remaining URLs will be detected as additional URLs of the same group. However, the following URLs will still be scanned, but only for one URL of the group and not repeatedly anymore:
www.your-app.dev/shop/shirts/shirt_s_blue/detailswww.your-app.dev/shop/shirts/shirt_s_blue/commentswww.your-app.dev/shop/shirts/shirt_s_blue/comments/create
Contact Veracode Technical Support if you have further questions on fine-tuning your scan.
Seed URLs
Sometimes web applications have pages that are not linked anywhere and cannot be detected by the crawler. For example, the administrator login interface, such as https://your-app.dev/admin/login, for a web application might be intentionally not linked anywhere but should be scanned during the security scan.
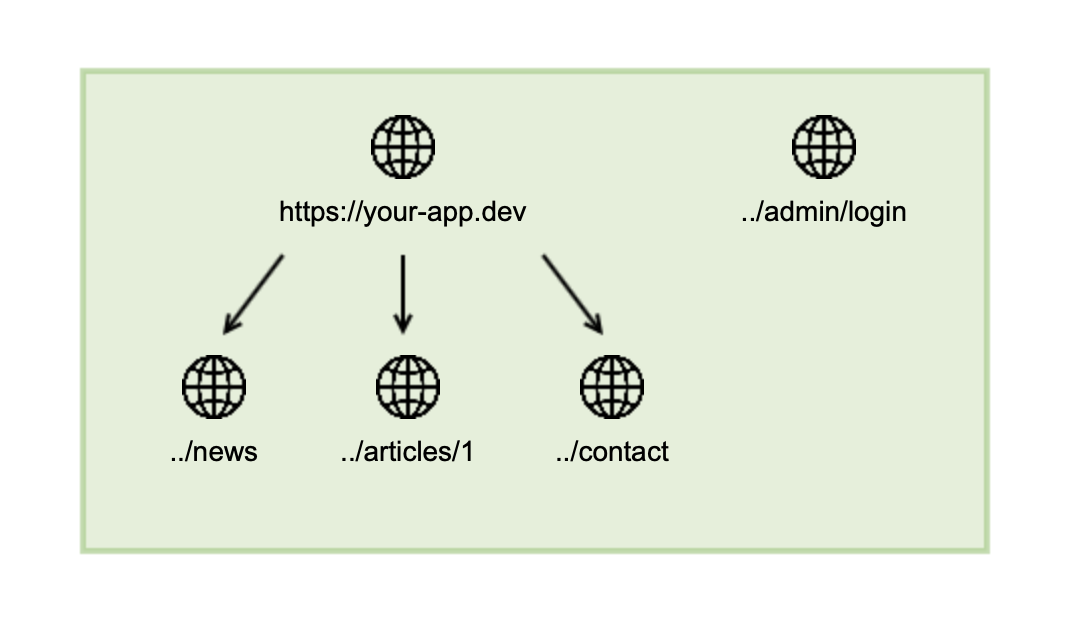
These pages can be manually added for crawling by specifying them as a seed URL in the configuration of your target. Remember that the service also checks if the seed URL is a subpath of your target URL to determine if it is allowed to be scanned. If this is not the case, but the seed URL should be scanned, you will need to add it to the permitted URLs.